*This “paper” was generated by ChatGPT based on the code, author prompt, and X/Twitter discussions.
Abstract
PredictiveChat introduces an innovative approach to leveraging large language models (LLMs) to anticipate user input, enabling instantaneous response generation in conversational AI systems. By predicting user messages and pre-generating responses, PredictiveChat aims to significantly enhance user experience through reduced response times. This paper outlines the system’s methodology, contrasts it with existing technologies, discusses its implementation, and explores potential future applications.
GitHub: https://github.com/yoheinakajima/predictivechat
Original X/Twitter Thread: https://twitter.com/yoheinakajima/status/1762313302863200658
1. Introduction
Conversational AI interfaces often suffer from latency, which can detract from the naturalness of human-computer interaction. PredictiveChat addresses this challenge by emulating the human ability to predict and formulate responses during conversation, thereby aiming to achieve “negative latency” in certain instances and almost zero latency in others. This system not only seeks to reduce wait times but also leverages the additional processing time for more thoughtful and contextually relevant responses.
2. Background and Related Work
2.1 Predictive Technologies in Conversational AI
While existing technologies like Google’s Smart Reply and Apple’s QuickType have introduced predictive text and response capabilities, they primarily focus on static predictions. In contrast, PredictiveChat dynamically anticipates the user’s complete input in real-time, offering a significant advancement over these earlier approaches.
2.2 Innovations in Latency Reduction
The discussion on Twitter highlighted several theoretical approaches and practical implementations relevant to PredictiveChat’s goals:
- Vector Store and Violation of Expectation: Inspired by @BloomBotAI, PredictiveChat utilizes vector stores as a cache mechanism, leveraging the psychological principle of “violation of expectation” to reduce latency.
- Kalman Filter Analogies: The system’s predictive mechanism draws comparisons to the Kalman filter, handling uncertainty and noise in real-time user input prediction.
- Chain of Thought Processing: PredictiveChat plans to use extra compute time for deeper processing, such as Chain-of-Thought or Retrieval-Augmented Generation (RAG), enhancing AI interaction models.
These discussions underscore the community’s interest in leveraging LLMs for predictive conversational AI, offering insights into potential improvements and innovations.
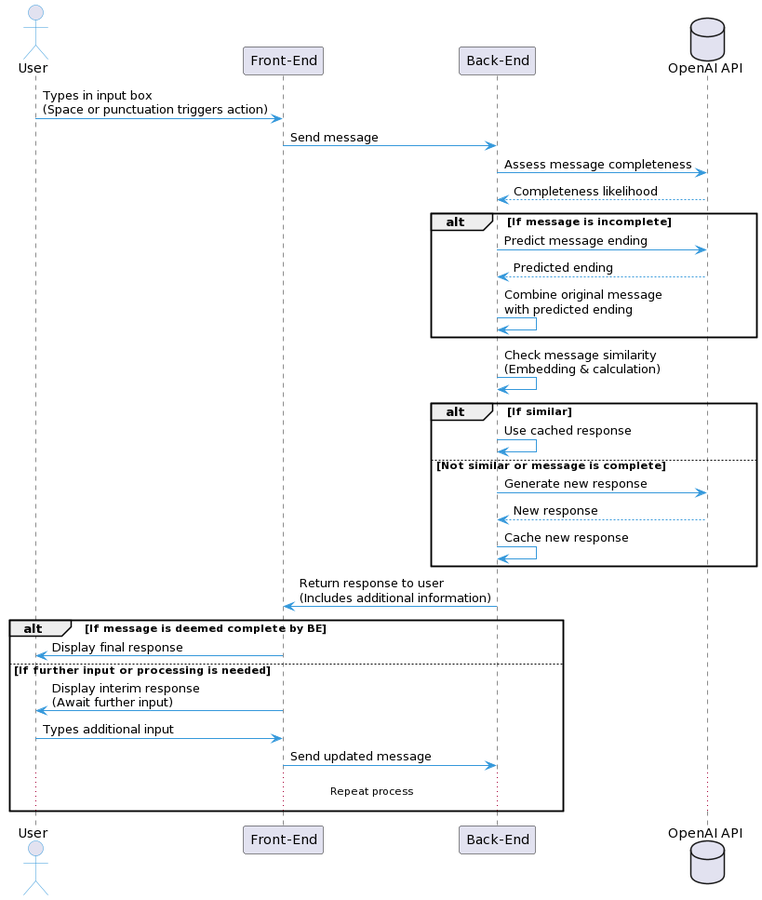
3. System Architecture and Implementation
PredictiveChat is built on a Flask web application framework and integrates with OpenAI’s GPT models for input prediction and response generation. Its architecture features three key components:
- Input Prediction Module: Utilizes partial user inputs to predict the remainder of the user’s intended message, leveraging a custom adaptation of GPT-3.5 for dynamic prediction.
- Response Generation Module: Generates potential responses based on both partial and predicted inputs, facilitating instantaneous or near-instantaneous replies once the user completes their message.
- Caching and Retrieval System: Employs a vector-based mechanism to store message and response embeddings, allowing for rapid retrieval of similar past interactions to further reduce response times.
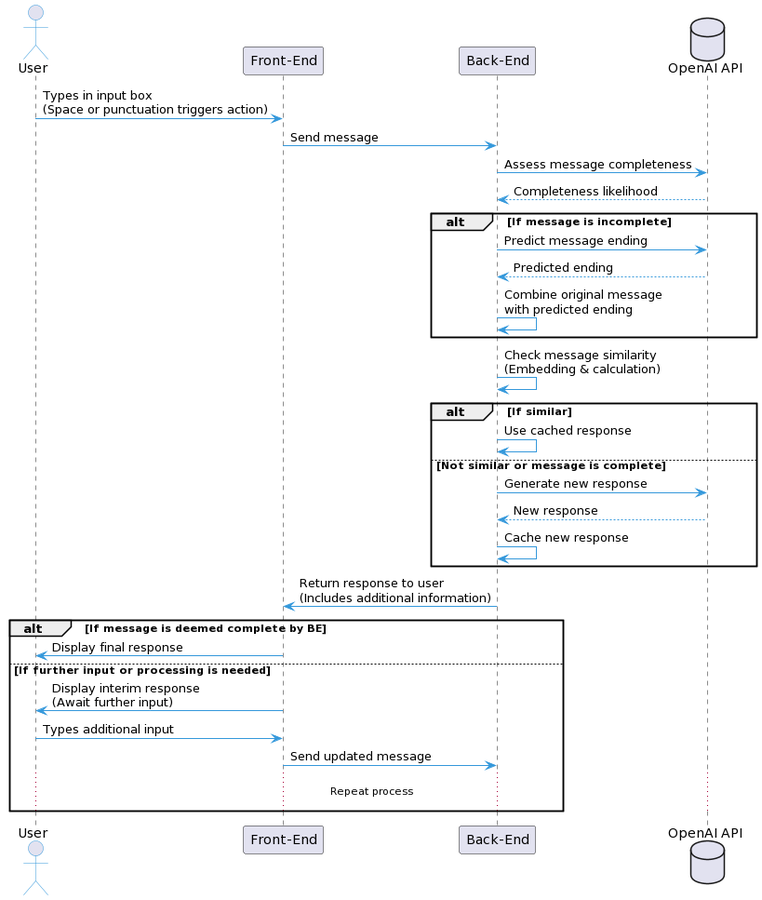
Data Flow and Processing
PredictiveChat’s innovative data flow begins with the user’s initial input, which is used to predict the message’s completion and generate a response preemptively. This approach has demonstrated the potential for “negative latency” in cases where the system mistakenly but accurately anticipates the user’s complete message, as well as almost zero latency when utilizing cached responses.
4. Evaluation and Insights from X/Twitter Discussion
While formal evaluation metrics and user studies are pending, initial observations suggest that PredictiveChat can achieve significant reductions in response latency. The Twitter discussion provided valuable insights into practical and theoretical innovations, highlighting the system’s potential to revolutionize conversational AI with features like:
- Speculative Decoding: Speeding up inference in LLMs by decoding future inputs preemptively.
- Filler Words and Stalling Phrases: Enhancing naturalness in AI interactions by incorporating filler words during processing times.
- Speech-to-Speech Models: Expanding PredictiveChat to direct speech-to-speech interactions, eliminating the need for text intermediaries.
See full summary of X/Twitter discussion here, and for original input, look at the replies to this post.
5. Future Directions
PredictiveChat’s future opportunities include integrating Chain-of-Thought processing and/or RAG in a chat context, and exploring the potential for preemptive actions beyond chat, such as in user need prediction and robotics. The pattern could also investigate multimodal predictions to enrich interactions across different sensory inputs.
6. Conclusion
PredictiveChat offers a novel solution to the longstanding issue of latency in conversational AI. By predicting user inputs and leveraging advanced LLMs, the system promises a significant leap towards more natural and efficient human-computer interactions. Future enhancements, informed by ongoing discussions and technological advancements, will continue to refine and expand PredictiveChat’s capabilities.
Acknowledgments
We thank the contributors to the Twitter discussion for their insightful comments and suggestions, which have greatly enriched our understanding and perspective on the future of conversational AI.
Leave a Reply